LiDAR数据处理中的性能优化笔记

今年参与了从零开始的激光雷达项目,学到不少的技术也踩了无数的坑,主要将OpenCl和性能优化部分记录在此。
lidar介绍
激光雷达(LiDAR, Light Detection and Ranging)是一种主动式的三维测距传感器。与相机依靠环境光成像不同,激光雷达具有主动发光探测物体的能力,通过接收反射光的飞行时间来计算物体物理世界的三维x,y,z。
测距原理
通过spad(Single Photon Avalanche Diode,单光子雪崩二极管)传感器,其很灵敏可以检测到单个光子到达事件。测距流程如下:
激光器发出一束极短的脉冲光,光照射到目标物体后反射回来;
SPAD 阵列探测到返回光子,电子电路记录“光子到达时间”;
经过多次发射—接收周期后,统计每个时间段内光子的数量;
就得到了一个 “光子到达时间分布直方图”。如下图。本身会有一些环境光带来的噪声,所以图像类似高斯分布。
直方图中的峰值可以认为是物体反射回的光子,通过峰值对应的时间,就可以计算目标物体的距离。实际会有多个反射峰,还需要算法进行选择。
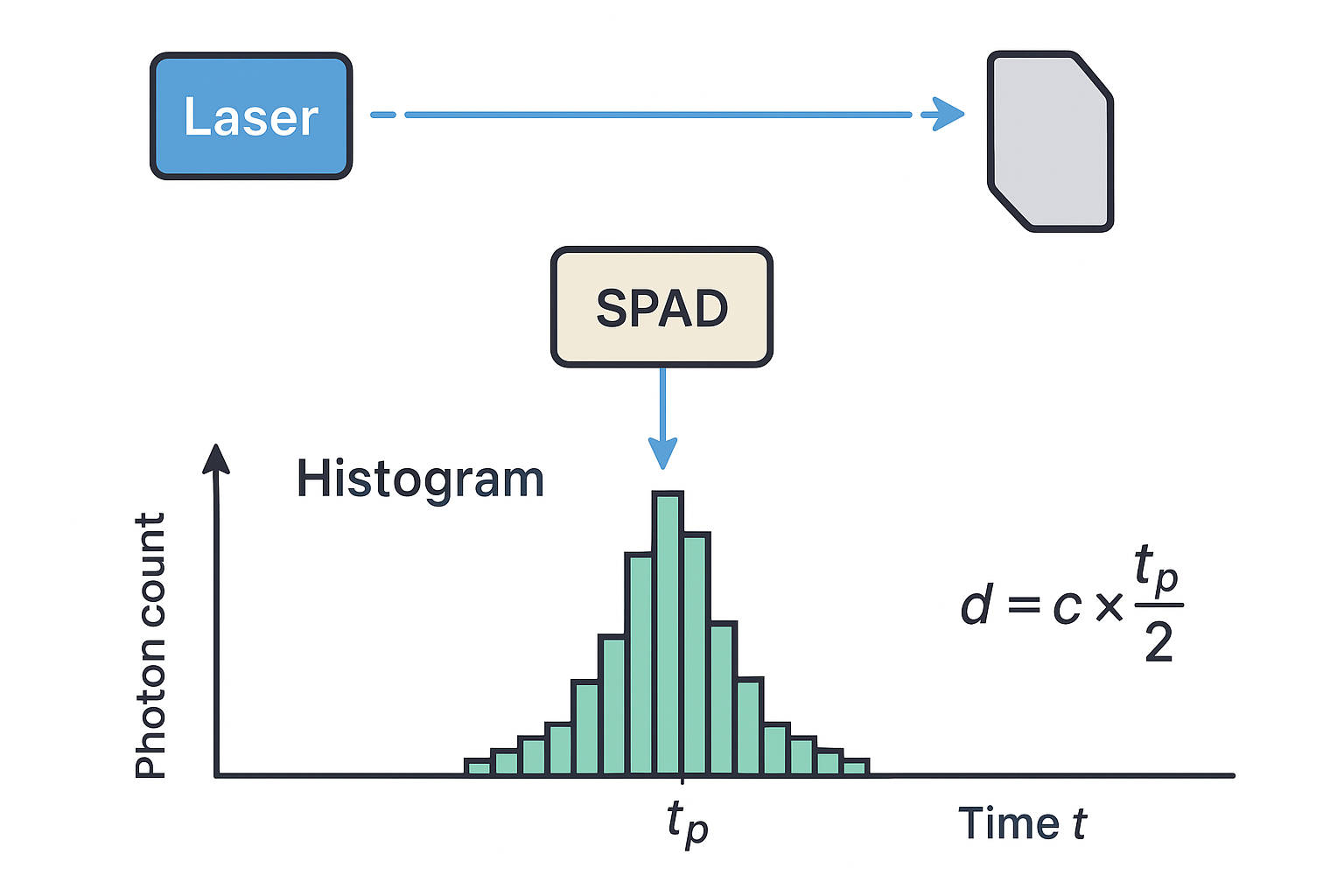
算法处理
每个像素点芯片都会输出一个多峰的直方图。算法会进行峰值选择和测距修正,噪点滤除等操作。
OpenCl
OpenCL(Open Computing Language) 是一个由 Khronos Group 制定的开放的异构计算标准。它定义了一套跨平台的并行计算框架,用于在不同的硬件设备(CPU、GPU、DSP、FPGA、NPU 等)上执行通用计算。
异构计算:是指在同一系统中,使用不同指令集架构或计算模型的处理单元协同完成计算任务的技术。
在我们soc板子上以下三种设备都存在,不同设备有不同的特点:
- CPU:并行计算单元少,缓存较大,控制结构逻辑丰富,适用执行具有控制结构、存储器访问不规则、并行度较低的程序。
- GPU:并行度高、适用计算密度大、控制结构相对简单的程序。GPU上执行的程序也可以分支判断只是可能会影响计算性能。
- NPU:专门设计用来进行神经网络模型推理。
在本项目中使用OpenCl在GPU上进行算法处理,相对于CPU计算速度大概有2~3倍的提高。
基本流程
简单讲:在主机端(CPU程序)调用OpenCL的API将计算任务提交到设备端(GPU)上执行。
下面具体介绍任务提交的步骤。
定义设备端执行程序
程序使用OpenCL C语言编写,语法基本和C语言一样,多了一些扩展语法。
例如,一个简单的向量加法函数:
__kernel void vector_add(__global const float* A, __global const float* B, __global float* C) { int gid = get_global_id(0); C[gid] = A[gid] + B[gid]; }__kernel 表示这是一个可在设备端执行的函数;
__global 表示参数是 GPU 全局内存;
get_global_id(0) 用于区分不同的并行工作项(线程 ID),不同工作项可以并行执行计算。工作项就是GPU执行单元和线程一个概念
主机端环境准备
主机端通过API找到支持OpenCL设备、创建上下文、创建命令队列。
上下文:表示一个或多个设备的执行环境,在同一个上下文中的设备之间可以共享内存对象。
命令队列:是主机端(Host)向设备端(Device)提交任务的通道。
编译设备端执行程序
主机端通过API编译OpenCL C源码生成程序对象,从程序对象获取要执行的kernel函数。
准备数据
将数据复制或者引入到设备端可以访问的存储空间中。
对于拥有独立显存的GPU设备这一步无法避免需要将主存中的数据拷贝到设备端。但ARM的GPU是和CPU共享主存的,所以可以有零拷贝的优化。
提交运行
将数据和内核函数绑定提交到命令队列中。指定工作项个数和维度,也就是并行线程数量。
同时可以将工作项划分工作组,在工作组内的工作项可以访问组内共享的局部存储。后边会详细介绍为何会有工作组概念。
读取结果
使用API同步等待任务执行完毕,将数据取回主机端。
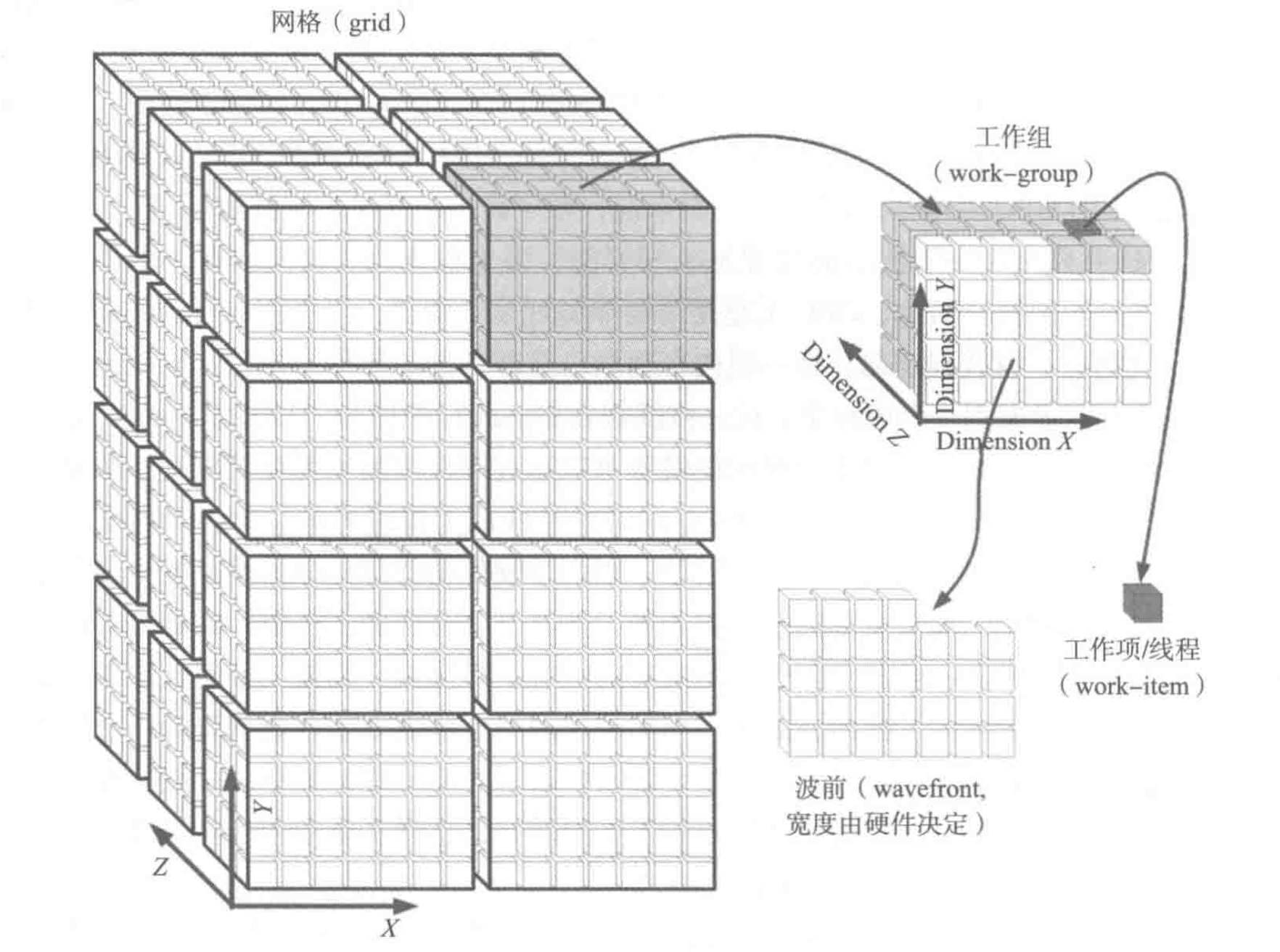
并行线程组织
GPU的一个内核包括多个计算和内存处理流水线,支持多个工作项/线程同时执行。这些同时运行的线程在OpenCl术语称为“波前”(wavefront)。
如果GPU核心只允许一个波前运行是不划算的,因为线程总要访问内存,由于内存延迟计算硬件只能闲置。因此,需要准备多个波前,当当前波前访问内存就换一组内存数据准备好的线程来执行。所以需要将一批线程分配到一个内核中,这一批线程就被称为“工作组”。由于被分配到一个内核中,所以共享内核的局部存储。
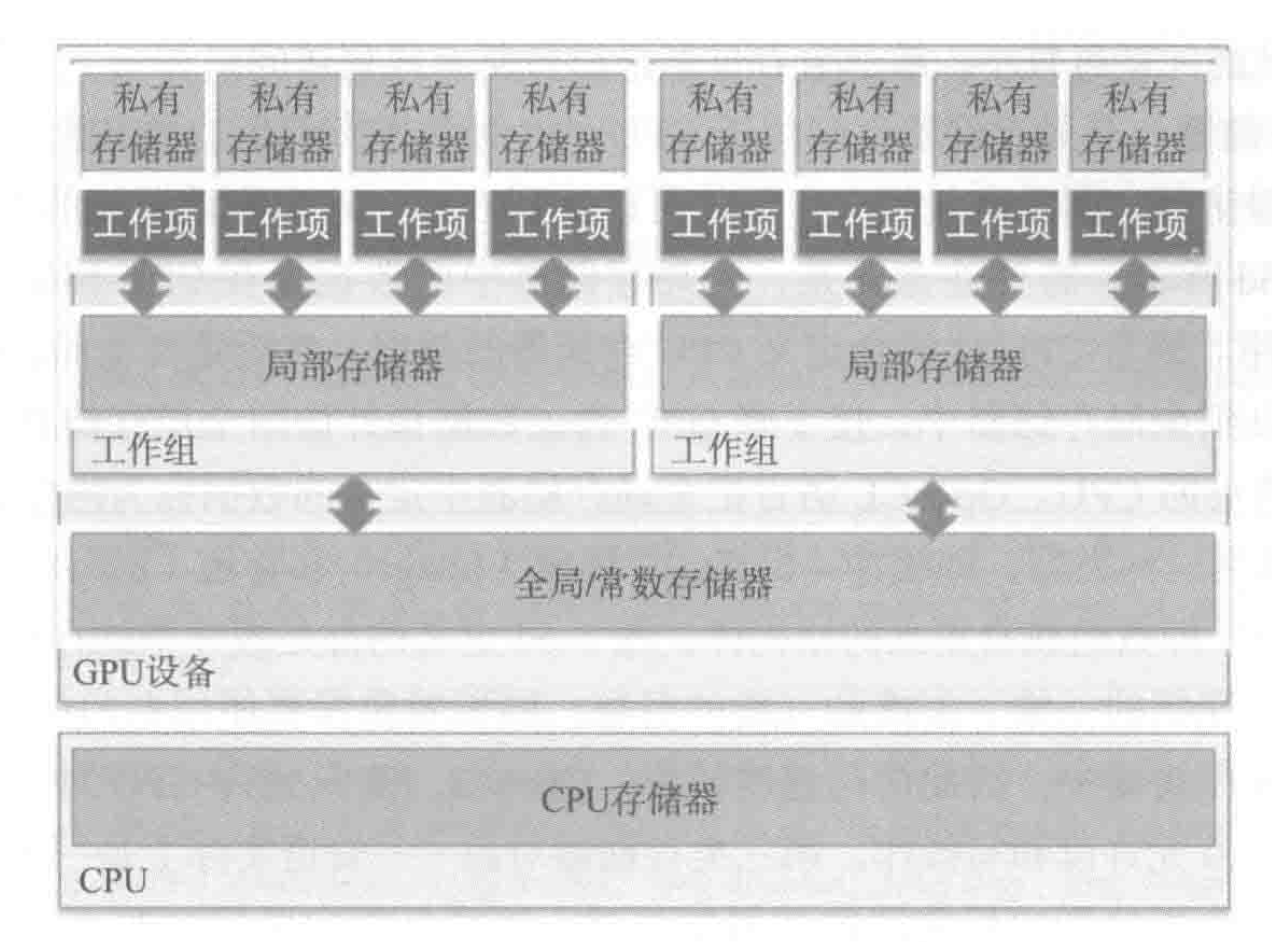
内存模型
如下图,在OpenCl中分为4个逻辑空间,越往上访问速度越快、存储空间和共享范围越小。内存访问会很影响计算速度。
同步
在OpenCl的模型中,每个工作项执行时独立,一个工作项的写操作和另一个工作项的读操作是没有顺序保证的。其采用宽松的同步和内存一致性模型。
对于设备端全局同步只在kernel执行完成后,位于不同工作组的两个工作项没有方法来确定执行顺序。在同一工作组对共享的局部存储器OpenCl提供了barrier函数来同步。
对于主机端在提交任务时可以使用事件来进行同步和保证任务依赖关系。每个任务都会返回事件对象,提交任务时可以指定依赖的事件对象,当依赖的事件对象完成时,当前任务才会被执行。
性能优化
由于该项目需要在3ms处理完一个子帧数据100ms内处理完一个完整帧数据,所以踩了很多性能上的坑。其中未勾选的是还未进行尝试的优化项。
OpenCl优化
OpenCl的性能优化分为设备端和主机端的优化。
设备端
- 编译OpenCl C源代码时增加编译参数 -cl-fast-relaxed-math -fkernel-vectorizer -fkernel-unroller。
- 减少全局内存访问,重复多次访问的全局内存先拷贝到局部内存中,保证全局内存只访问一次。执行时间从1.8ms优化到900多微妙。
- 提高并行数量: 重新设计算法实现和使用子内核,实现更多工作项的并行。
- 使用half半精度浮点数,减少精度提高执行速度。
主机端
目前主机端是主要瓶颈。解析v4l2的原始数据放入OpenCl的buffer再提交到执行队列中的操作容易超时。
- cl::Kernel初始化需要大概100微妙,首次初始化需要200+ms。解决:复用kernel。
- 将OpenCl buffer映射到主机端内存空间中耗时异常。由于映射操作也需要放入命令队列中执行,而命令队列是串行的,所以任务执行速度也会影响到映射操作。
- 提交到队列的任务不会立即执行,需要显示调用wait或者flush才会执行。任务未及时执行增加映射延迟。
- 使用arm对OpenCl的扩展cl_arm_import_memory_host直接引入主存内存,不用进行映射操作。由于内存需要4k对齐分配时存在固定百级微妙耗时。
- 使用arm对OpenCl的扩展cl_arm_import_memory_dma_buf直接引入v4l2的数据实现零拷贝。需要将原始数据解析放在OpenCl中。
- rk平台存在cpu负载低时降频的问题,也会导致映射操作延迟增加。
其它
CPU解析原始数据延迟11ms过高,通过编译开启-o3和release后耗时不到1ms。
v4l2驱动原始数据通过mmap方式获取没有cache,即使只memcpy耗时也超过3ms。使用dma-buf方式从驱动获取数据带cache,memcpy降低为170+us。
cache局部性对性能的影响,将循环遍历数据放入独立的vector(内存访问连续)而不是放入结构体vector(内存访问跳跃)中,优化时间从60ms到30ms。
一般定义结构体数组的方式(AoS, Arrays of Structure):
struct Point { float x, y, z; }; std::vector<Point> points;对连续访问单个字段时缓存局部性差。
改成SoA(Structure of Arrays)布局,将每个字段单独存储在一个数组中,访问单个字段时缓存局部性好。
struct PointSoA { std::vector<float> x; std::vector<float> y; std::vector<float> z; };指令集优化,编译选项增加-march=armv8-a 优化时间 22ms=>18ms。
工程
dotfile
项目中用到一些dotfile(以“.”开头的配置文件),为了让团队在代码风格、静态检查保持一致。
| 文件名 | 作用说明 | 主要用途 |
|---|---|---|
| .clang-format | 定义代码格式化规则,如缩进、括号风格、空格、命名规则等。 | 统一代码风格,可用 clang-format -i *.cpp 自动格式化。 |
| .clang-tidy | 配置 clang-tidy 静态代码检查规则,指定启用或禁用哪些检查项。 | 发现潜在 bug、性能问题、API 误用、现代化建议(如 modernize-*)。支持对变量命名格式约束,如驼峰命名法、下划线命名法等。 |
| .cmake-format | 规定 CMakeLists.txt 的格式化风格(缩进、换行、对齐方式等)。 | 保持 CMake 文件可读性一致,用 cmake-format 自动格式化。 |
| .editorconfig | 通用编辑器配置文件,控制缩进、换行符、编码、末尾空行等。 | 跨编辑器(VSCode、CLion、Vim)统一基本编辑行为。 |
宏定义
宏定义和C++模板都是属于元编程,可以在编译期对自身代码进行修改。可以减少重复代码提高开发效率。
例如生成SoA布局的结构体,同时提供reset()重置各个字段的功能。可以做到新增字段只增加必要提供的信息(字段名、类型、默认值等)减少重复代码。
#define DEFINE_SOA_STRUCT(name, FIELDS) \
struct name { \
FIELDS(DEFINE_FIELD_VECTOR) \
void reset() { FIELDS(RESET_FIELD) } \
};
#define DEFINE_FIELD_VECTOR(type, name, size, value) std::vector<type> name = std::vector<type>(size, value);
#define RESET_FIELD(type, name, size, value) std::fill(name.begin(), name.end(), value);
#define LIDAR_POINT_FIELDS(X) \
X(float, x, kFramePixelSize, 0) \
X(float, y, kFramePixelSize, 0) \
X(float, z, kFramePixelSize, 0) \
DEFINE_SOA_STRUCT(LidarPointCollection, LIDAR_POINT_FIELDS)
// 展开为
struct LidarPointCollection {
std::vector<float> x = std::vector<float>(kFramePixelSize, 0);
std::vector<float> y = std::vector<float>(kFramePixelSize, 0);
std::vector<float> z = std::vector<float>(kFramePixelSize, 0);
void reset() {
std::fill(x.begin(), x.end(), 0);
std::fill(y.begin(), y.end(), 0);
std::fill(z.begin(), z.end(), 0);
}
};