记一次数据竞争导致内存损坏的coredump - 问题诊断

此次coredump断断续续查了约两个月才查明原因,迄今为止遇到最棘手的问题,深刻的体会到debug C/C++内存损坏是多么痛苦。为了debug还写了两个内存检测工具,可惜最终还是通过注释代码和人肉检查找到了问题根因,不过自制的检测工具还是能把模拟的demo检测出来问题,还是比较有成就感。
前置知识
内存管理器
如果想要对内存损坏有一个深刻意识需要对内存分配器有一个初步的认识,接下来对其做基本概念介绍。
堆内存(Heap Memory)是由内存管理器进行管理的,用户通过void *malloc( size_t size )申请堆内存块,通过void free(void *)将申请的内存块还给内存分配器。一般我们使用的内存管理器是glibc中的ptmalloc。
在linux中内存管理器通过brk和mmap系统调用向操作系统申请一大块内存进行管理,用户申请的内存优先在申请的大块内存中分配,从而减少系统调用的次数。通过brk控制下图1中狭义的Heap Segment区域扩大或缩小,其作为主线程的堆内存由内存管理器管理。对于其它线程则是通过mmap在Memory Mapping Segment区域申请内存块使用,从而减少多线程共享内存块。所以内存管理器的难点就是合理化利用从操作系统申请的一大块内存,在用户malloc申请内存时能及时找到满足用户申请大小的内存返回给用户;在用户free释放内存能合理的管理这些被释放的内存块,比方说合并相连的内存块减少内存碎片。
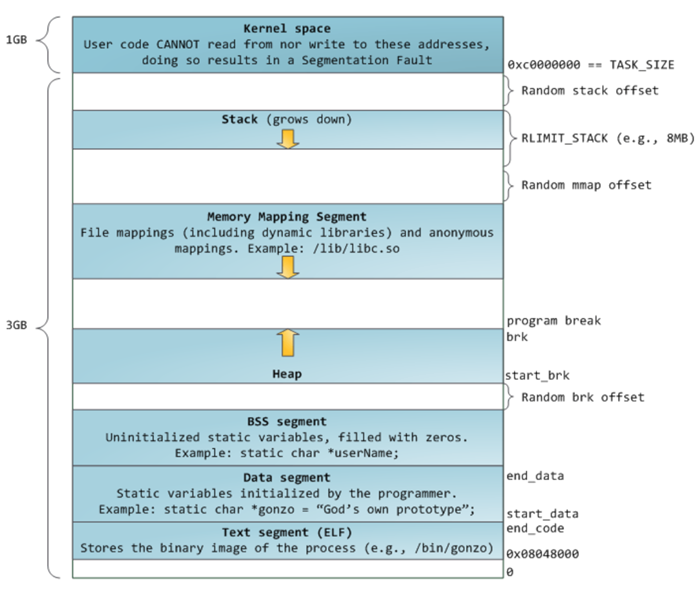
对于ptmalloc有如下一些数据结构:
Arena
用于管理向操作系统申请的内存块,分为主线程的main arena和线程的thread arena。main arena是通过
brk系统调用在空间用尽时可以拓展,而thread arena无拓展能力,所以可能会管理多个内存块。内存块在ptmalloc中用struct heap_info作为header保存元信息。arena使用struct malloc_state作为header保存元信息。另外对于一些用户线程数量高于cpu核数,每个线程分配一个arena开销过大,所以thread arena其实是受限于cpu核数,总之不是一个线程就对应一个arena。
Chunk
用于管理分配给用户的内存块,主要有Allocated chunk已经分配给用户的内存块和Free chunk用户释放的内存块。其header数据结构称为
malloc_chunk。Allocated chunck已经分配给用户的内存块

Allocated chunk已经分配给用户的内存块 其中左方第一个箭头chunk表示起始地址,mem表示分配给用户的起始地址,next_chunk为下一个chunk的起始地址同时也是分配给用户的结束地址。This chunk size是分配的size大小,其有对齐的需求,所以后三位都为0,为了节省空间,将其利用放入三个标志位。N表示该chunk是否为thread chunk,M表示是否是mmap分配的chunk。P表示前一个chunk是否被分配。
Free chunck
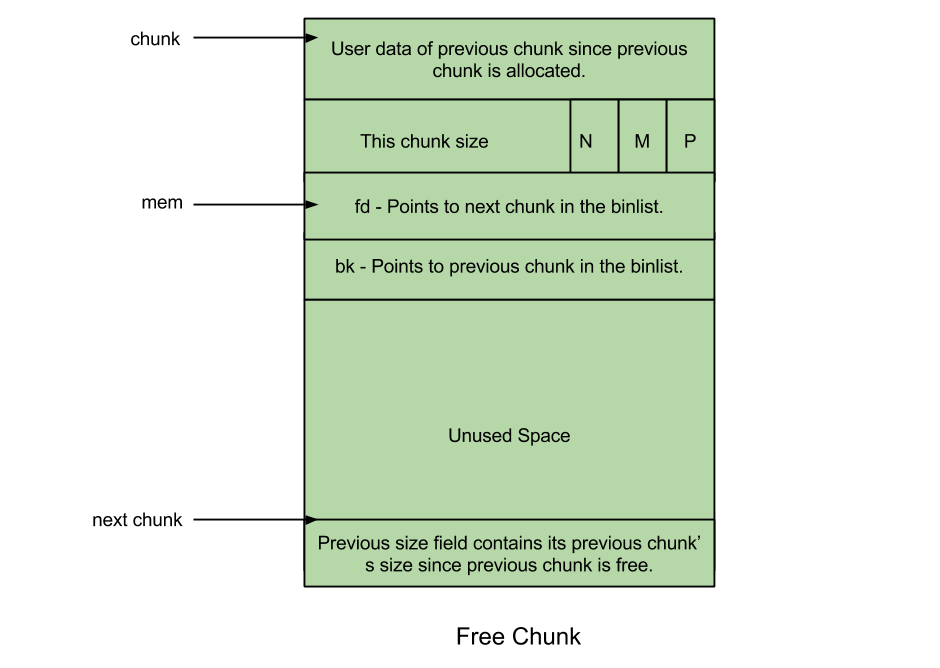
free chunk已经分配给用户的内存块 比起Allocated chunck增加了两个指针,指向同一个bin中前后的free chunk。bin就是用来管理free chunk的数据结构。
可以见得存储前一个chunk的是否分配和分配大小就是为了在释放时检查如果前后的chunk也是free chunk可以进行合并,减少内存碎片。
Bin
bin就是用来管理free chunk的数据结构,其包含Fast bin、Unsorted bin、Small bin、Large bin等,已经释放的chunk会根据一些规则放入不同的bin中,设置多个bin主要是满足用户的不同分配内存大小,加快找到合适的free chunk分配给用户。
根据上述的介绍可以了解到,假设用户拿到分配的内存,不小心修改了不是所申请范围的内存,就可能修改到内存分配器存储的一些元信息,在之后的内存管理器执行时造成错误。这也是我们见到程序挂在malloc相关函数中一个可能的原因。
内存损坏(memory corruption)
内存损坏通常是对不是自己向内存管理器申请的内存块进行操作,而在大多数情况下对该内存操作对操作系统角度看却是合法的,因为访问的地址是内核分配给进程的空间,所以程序不会马上崩溃,数据被悄悄修改,最后可能会挂在不相关的地方。《高效C/C++调试》2书中写道:
调试内存损坏的真正挑战在于,程序错误时并不能揭示导致错误的有缺陷的代码。通常,程序在有bug的代码做出错误的内存访问时,不会显示任何症状,但是程序中的某个变量意外地被改变为不正确的值。在一些文献中,这被叫作传染。随着程序继续运行,该变量会感染其他变量。这种错误传播最终会发展为严重的失败:程序要么崩溃,要么生成错误的结果。由于导致错误的原因和结果之间的距离很长,崩溃时的变量和执行代码与实际错误往往没有关联,而且在时间和位置方面可能会表现出很多随机性。
所以如果程序崩溃在错误代码运行时,那问题就很好debug。对于更“高级”的语言像java/python有越界检查和垃圾回收gc机制基本可以做到程序崩溃的地方就是错误代码运行的地方,而对于C/C++就不一定了,当然也不用为越界检查和gc付出“代价”。参考《高效C/C++调试》堆内存损坏的常见几种类型,如下:
内存溢出和下溢
用户代码访问超出内存管理器分配的内存(溢出)或者访问可用内存之前的内存块(下溢)。可能会损坏堆元数据结构,导致下一个块被释放或者分配时产生未定义行为。而且也不一定会内存损坏,因为内存块有最小块大小和对齐的要求,可能实际分配给用户的内存大于用户请求大小,破坏的可能是填充的内存,就不会有影响。
操作已经释放的内存
另一种情况是操作已经释放的内存,当用户操作空悬指针或引用时会造成内存损坏,同样症状因许多因素而异,例如,访问的内存已经还给内核,则程序因非法地址访问直接崩溃;释放的内存可能再一次分配给用户,从而导致数据对象被意外破坏;如果内存被内存管理器缓存,修改其可能会破坏堆元数据。
使用未初始化的值
对于未初始化的变量具有随机不可确定的值,如果是恰巧是以前变量留下的野指针,一旦使用也会造成内存损坏。不过此类问题通过代码静态检查一般就可以发现,很好避免。
内存调试工具
根据《高效C/C++调试》书中所写,内存调试工具的大致可以分为3中类型:
填充字节方法
在每个分配的内存块开头和结尾添加额外的填充字节,内存溢出和下溢的代码就会修改填充字节,调试工具可以在内存分配api的入口(malloc和free函数)检查这些填充字节,如果发生填充字节被修改,就表示发生了内存损坏,报告错误的堆栈等信息。
系统保护页方法
在可能内存块前后设置不可访问的系统保护页,程序试图非法访问受保护的内存时,马上就会停止执行程序,因此可以找到具体越界的代码。但是,频繁地设置系统保护页会调用系统调用(linux下mprotect函数)有一定的时间消耗,有可能会改变程序的行为,使问题无法复现。
影子内存方法
在内部使用影子内存来跟踪程序的内存使用情况,每次内存访问都会更新影子内存,发生错误时,可以立即发现,但是对程序的性能影响较大。Valgrind的memcheck工具和asan都属于这一类型,平均性能损耗分别是10~20和2倍左右。
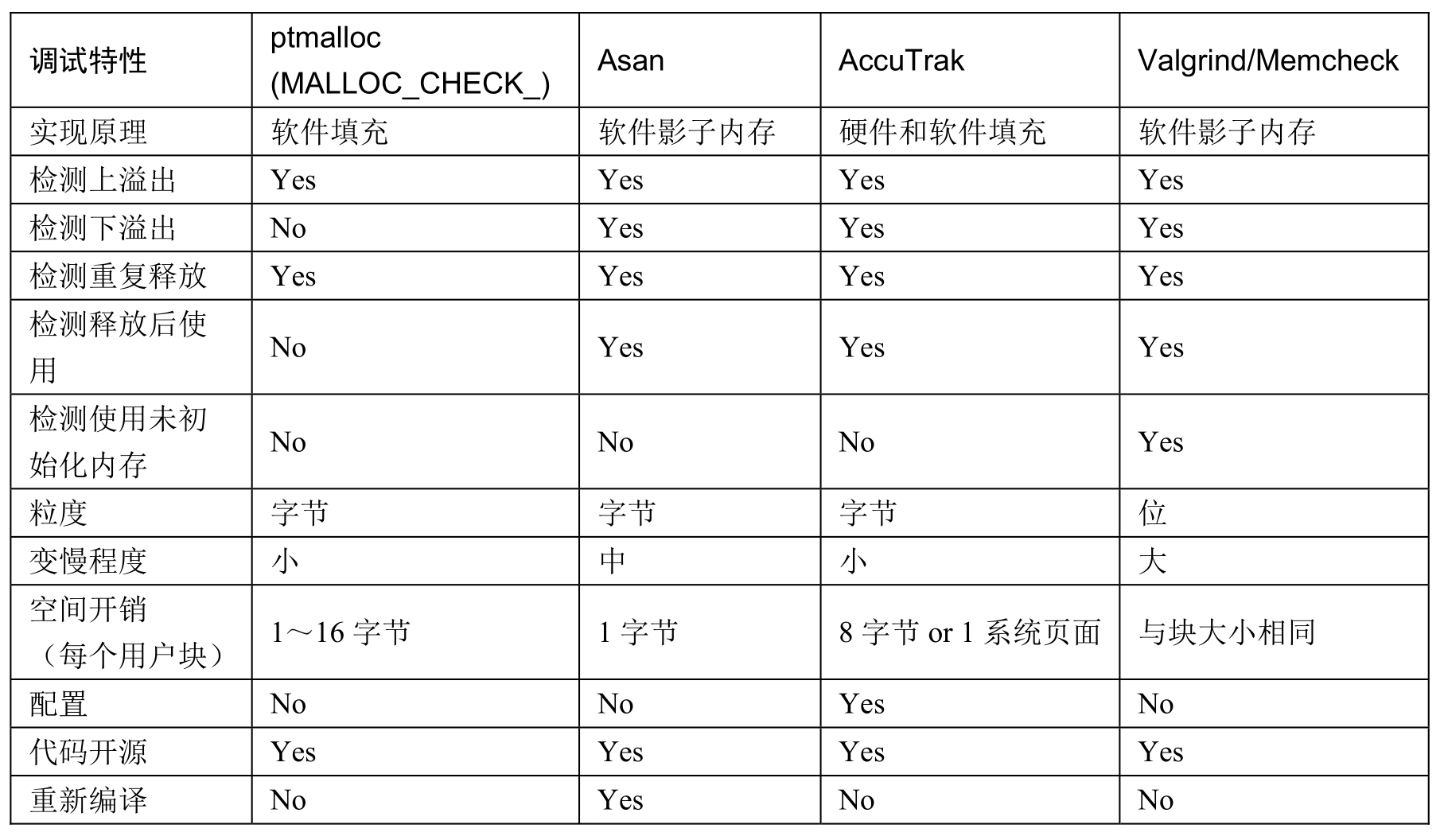
如下图,目前主流的内存检测工具对比。图来自《高效C/C++调试》,其中AccuTrak是该书作者开发的工具也加入了对比。
问题排查
软件是运行在arm板子有操作系统的车端状态机模块。该问题有稳定复现的方法,虽然需要几个小时才能复现。
coredump分析
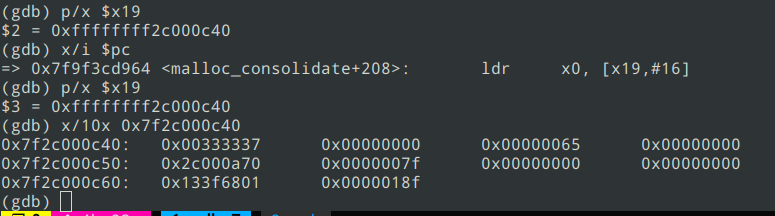
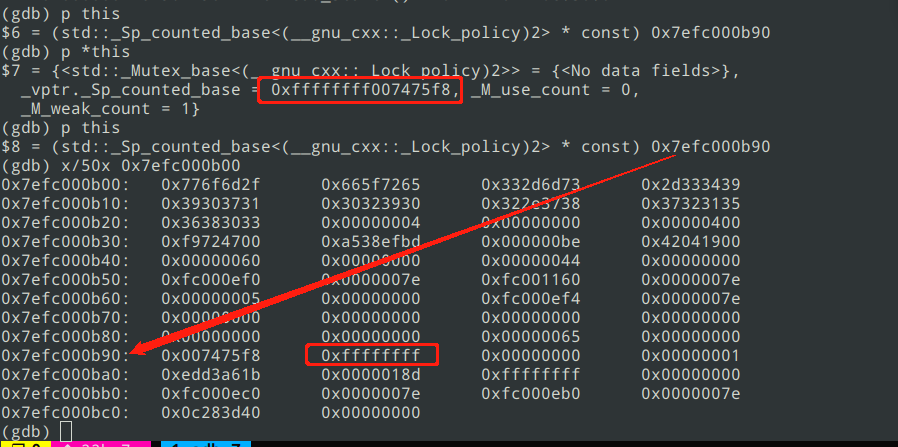
此版本coredump的堆栈不固定,一般最后都挂在malloc_consolidate函数中。从最后一条指令看出x19寄存器存储的指针高4字节被修改为0xffffffff,通过堆上前后数据特征,可以确定真正合法的地址是0x7f2c000c40被篡改为0xffffffff 2c000c40。
而在之前的版本中,coredump多是在另一个地方,堆上对象虚表指针的高4位被修改为0xffffffff。
debug之前的版本的coredump时,曾经在对象操作前后打印其虚表指针,明确看到其在执行完某个rpc操作后指针被篡改,当时一直怀疑的点是rpc操作中操作堆内存溢出,修改了虚表指针。在之前版本中着急发版没有找到根因,通过改写避开了coredump堆栈的代码。
分析过程
最初通过coredump的分析主要猜测原因是内存溢出。分析多个coredump时,尽管对比了被篡改数据前后的内存值,并未发现多个coredump有明显一致性的值。使用了MALLOC_CHECK、Valgrind/Memcheck工具和自制的两个内存检测工具,但都未找到问题所在。由于在编译SDK不支持,未使用asan工具。为了进一步排查问题,采用了“笨”办法,一点点注释怀疑的代码并尝试复现。
然而,最终通过自制的内存越界检测工具未能复现coredump的现象,因此认为不太可能是内存溢出修改导致的问题。经过一夜的思考,我想到了另一种可能性:多线程共享变量。如果一个线程在析构时,另一个线程还在使用这些变量,就可能导致coredump。最后,在注释了几个线程的启动后,通过代码review发现项目中存在这种竞态条件,导致操作已经释放的内存,并将其修改为-1(0xffffffff)。写了一个小demo模拟,可以复现这个问题。通过自制的堆数据释放后使用的内存检测工具也检测出了问题。
通过修改此处的代码,经过两天的压测,问题未再复现。
问题原因
原因简单讲就是对ros::Timer对象,在timer回调线程中调用其stop方法,另一个线程在某些条件下会销毁该对象。即
// thread 1
timer = n.createTimer(ros::Duration(1), std::bind(&TimerTester::fun1, this));
// thread 2
timer.stop();在thread 1中对栈上timer重新赋值,会将之前的timer销毁。虽然timer是栈上变量,但其内部申请了堆内存。其stop函数实现如下,其中正好有赋值-1,并且也能看出stop函数并不是线程安全的。
void Timer::Impl::stop()
{
if (started_)
{
started_ = false;
TimerManager<Time, Duration, TimerEvent>::global().remove(timer_handle_); // line6
timer_handle_ = -1;
}
}同事提出一个问题,即在timer销毁时也会调用stop函数,从代码和实际测试中能发现,stop函数在回调线程外部调用时如果回调函数正在执行会阻塞在line6等回调函数执行完毕。而stop函数在回调线程内部调用则不会阻塞等待(否则会产生死锁,ros内部通过tls线程局部存储变量判断是否在回调线程调用stop函数)。问题就是thread 1申请的内存释放前会调用stop函数,如果stop函数需要等待回调函数执行完成,则会等待thread 2执行完stop函数并且退出回调函数后才会释放内存,也就不会出现内存释放后使用的问题。
答案也很简单,由于stop不是线程安全的,所以完全可能thread 2执行stop把started设置为false,之后thread 1释放内存前调用stop由于started为false跳过阻塞等待直接执行完毕释放内存。
自制内存检查工具
本人在这次问题排查过程中,开发了两个内存检查工具,虽未用其查明根因,但在验证问题还是起到一定作用。两个内存检测工具都是通过LD_PRELOAD环境变量注入自己实现的malloc和free函数,在两个函数中进行一些检查,从而在用户使用有问题的地方能打印出堆栈提醒用户。并且工具实现较简单不会对程序有大幅影响,导致问题可能不复现。
代码注入方法总结
对于代码注入在《高效C/C++调试》2介绍了如下几种方法:
链接时替换
在生成可执行文件或共享库时,连接器发现如果存在多个实现与未定义的符号,会选择在搜索列表中最先找到的实现。所以可以将代理函数放在最前面,使链接器优先选择该函数。这种方式需要重新编译,对于未重新编译的第三方库来说注入就不会成功。
例如将自己实现的malloc、free、realloc等函数编译到目标文件my_malloc.o中,然后链接时将其放入其他目标文件之前,执行类似如下的命令:
g++ my_malloc.o other_object_files -o target预先加载函数
在运行时,系统加载器将读取环境变量
LD_PRELOAD预加载环境变量制定的动态链接库,但链接器尝试解析未定义的符号时,会优先使用库中的函数。该方法无需对程序重新编译。修改导入和导出表
运行时需要动态链接的函数时通过程序链接表PLT进行路由的,会在第一次调用进行符号解析找到函数对应的GOT表项中的函数地址,设置PLT表项跳转指令为GOT表项中的函数地址。我们可以通过修改GOT表项为代理函数,从而注入检查代码。每个so模块都有自己的GOT表所以需要对每个模块都进行修补,也可以进行细粒度的控制选择某些模块修补。
对目标函数进行手术改变
还有一种更具有侵入性的方式,修改目标函数的代码,通常不是直接覆写原始代码(由于原始代码空间较短无足够的空间容纳新代码),而是在函数开始时注入跳转指令,将其设置为代理函数的地址。该方法可以注入不是动态链接的函数。另外原始函数在.text段通常为可读的需要将内存保护模式从只读修改为科协,插入跳转指令后,再将函数的内存页面保护模式恢复成只读。
堆数据越界
原理
代码地址: 通过自定义的malloc和free等函数,在申请内存时内存块上下多申请几个字节并且放入魔数,在free时对上下魔数进行校验,如果发现被修改,则说明该释放数据在使用时出现了溢出情况,同时打印释放时的堆栈,以便提醒用户检查释放数据在之前的使用时有溢出的发生。
实例
对如下错误代码可以有效检测出来。
#include <iostream> using namespace std; int main(){ int *a = new(int); a[2] = 10; delete a; }缺点
- 由于只在释放时才会进行检查,所以对于一直运行的程序在其整个生命周期都存在的堆数据,只能使用ctrl+c提前结束程序才能触发检测。
- 使用mmap真实分配内存。所以分配内存的性能不如原始的ptmalloc,这一点可以进行优化。
堆数据释放后使用
原理
代码地址: 通过对用户调用free释放的内存块进行魔数填充,在一段时间后在去检查该魔数是否被修改,再还给操作系统。以此来检测是否用户存在释放后的内存块还在修改其内容。实现细节如下:
- 使用
__attribute__((constructor))在该工具so被加载时执行一些准备工作 - 使用
dlsym(RTLD_NEXT, "malloc")找到原始的malloc函数,内存实际的分配其实是转发给原始的malloc函数。 - 在用户调用malloc时保存其调用堆栈放入队列中,用户free时将内存块填充为魔数,并且检查队列是否满了,如果满了就取队头进行魔数校验,然后调用原始的free释放。如果魔数被修改则打印之前保存的申请时堆栈,调用terminate()生成coredump。
工具在检测到魔数被修改时,会打印申请内存块时的堆栈。
- 使用
实例
对如下错误代码可以有效检测出来。
#include <iostream> #include <thread> #include <chrono> using namespace std; void func() { uint i = 0; while (true) { int *a = new (int); a[0] = 0; delete a; if (i == 10) { a[0] = i; } ++i; } } int main() { std::thread t1(func); t1.join(); }缺点
- 由于
__attribute__((constructor))会在so被加载时执行,如果用户程序含有popen、system等新建进程时也会在该进程中执行一遍,所以可能会打印多次初始化的日志。 - 虽然对性能影响很小,但是也可能导致某些多线程原因导致释放后修改触发的概率减小。
- 由于